Streaming Video Representation
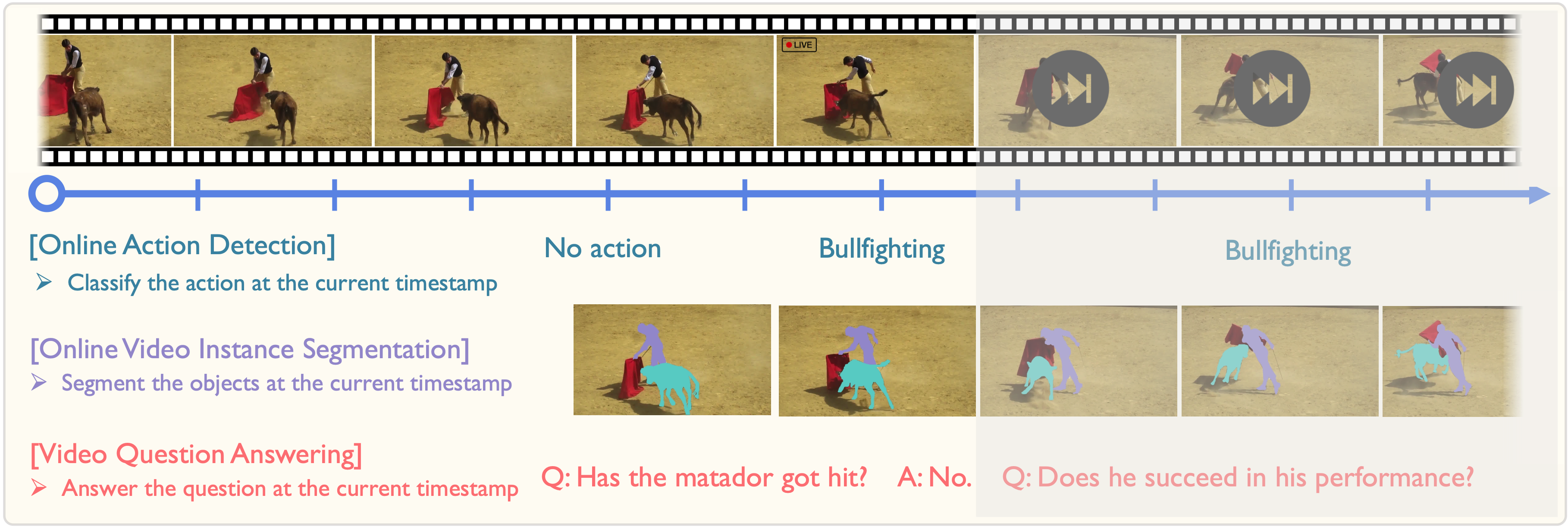
StreamFormer learns streaming video representations of various granularities through multitask training, making it applicable for diverse downstream tasks such as Online Action Detection, Online Video Instance Segmentation, and Video Question Answering.
StreamFormer learns streaming video representations of various granularities through multitask training, making it applicable for diverse downstream tasks such as Online Action Detection, Online Video Instance Segmentation, and Video Question Answering.
Method
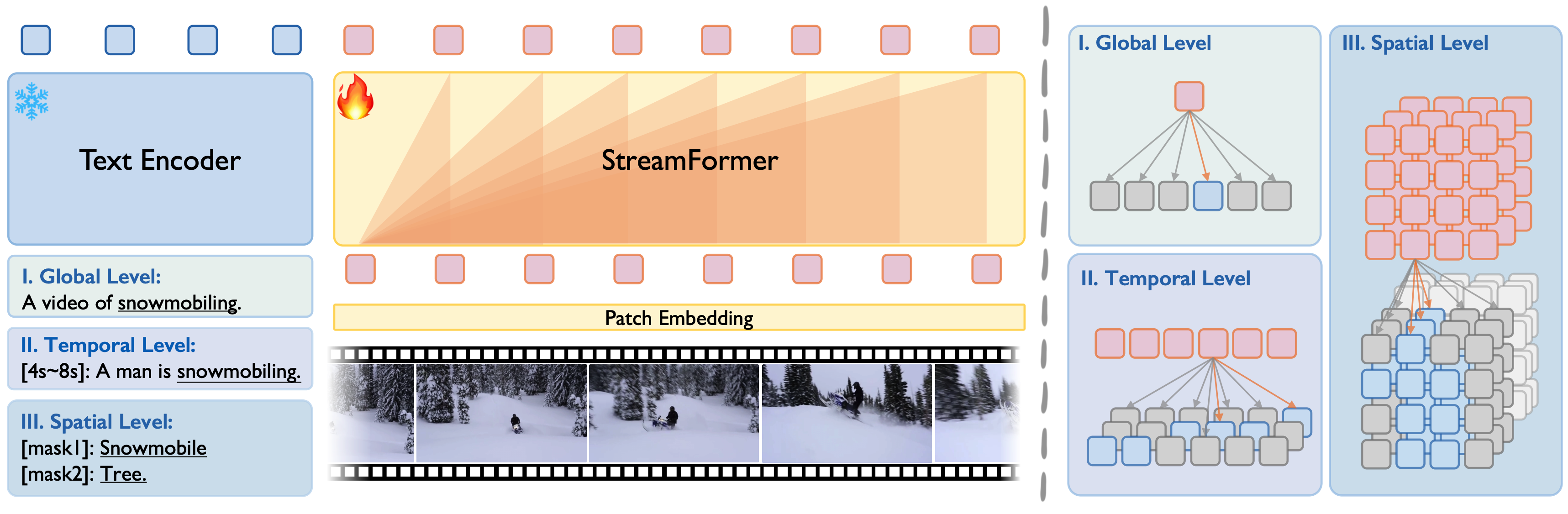
Overall framework of StreamFormer. Our StreamFormer is trained under a unified visual-language alignment framework,
enabling simultaneous understanding of global semantics, temporal dynamics, and fine-grained spatial relationships. Each level
utilizes features of different granularities: (i) last frame for the global level, (ii) per frame for the temporal level, (iii) and per frame per
patch feature for the spatial level.
Overall framework of StreamFormer. Our StreamFormer is trained under a unified visual-language alignment framework, enabling simultaneous understanding of global semantics, temporal dynamics, and fine-grained spatial relationships. Each level utilizes features of different granularities: (i) last frame for the global level, (ii) per frame for the temporal level, (iii) and per frame per patch feature for the spatial level.
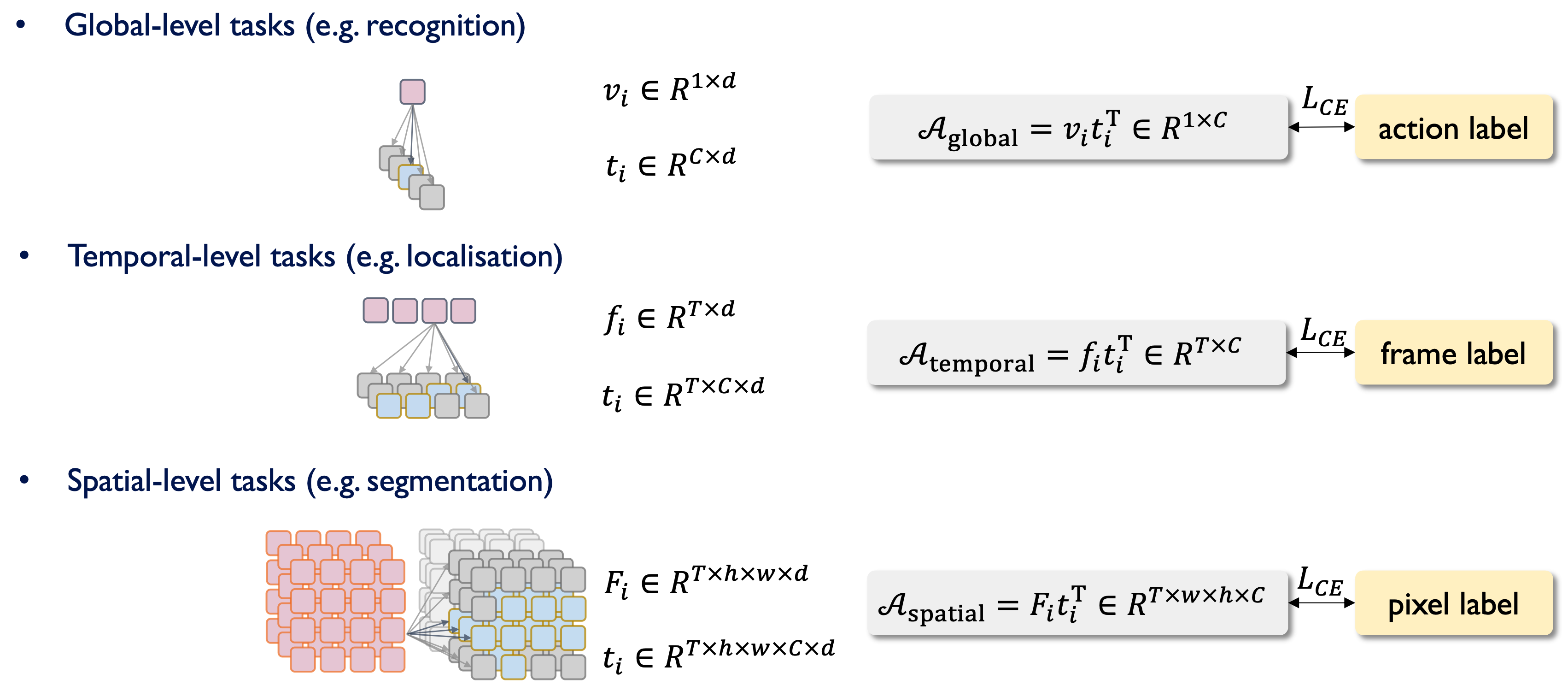
Specifically, we optimize the backbone with three complementary objectives:
(i) Global-level Tasks: The objective is to learn the global semantics of a video clip, encompassing both the primary action and the scene.
(ii) Temporal-level Tasks: The objective here is to develop fine-grained discriminative capabilities along the temporal dimension, enabling the model to perform tasks such as per-frame action understanding and perceiving events that occur across frames.
(iii) Spatial-level Tasks: The aim is to learn the fine-grained spatial relationships of a video clip, which involves understanding the interactions between different objects in all video frames.
Specifically, we optimize the backbone with three complementary objectives:
(i) Global-level Tasks: The objective is to learn the global semantics of a video clip, encompassing both the primary action and the scene.
(ii) Temporal-level Tasks: The objective here is to develop fine-grained discriminative capabilities along the temporal dimension, enabling the model to perform tasks such as per-frame action understanding and perceiving events that occur across frames.
(iii) Spatial-level Tasks: The aim is to learn the fine-grained spatial relationships of a video clip, which involves understanding the interactions between different objects in all video frames.
Experiments
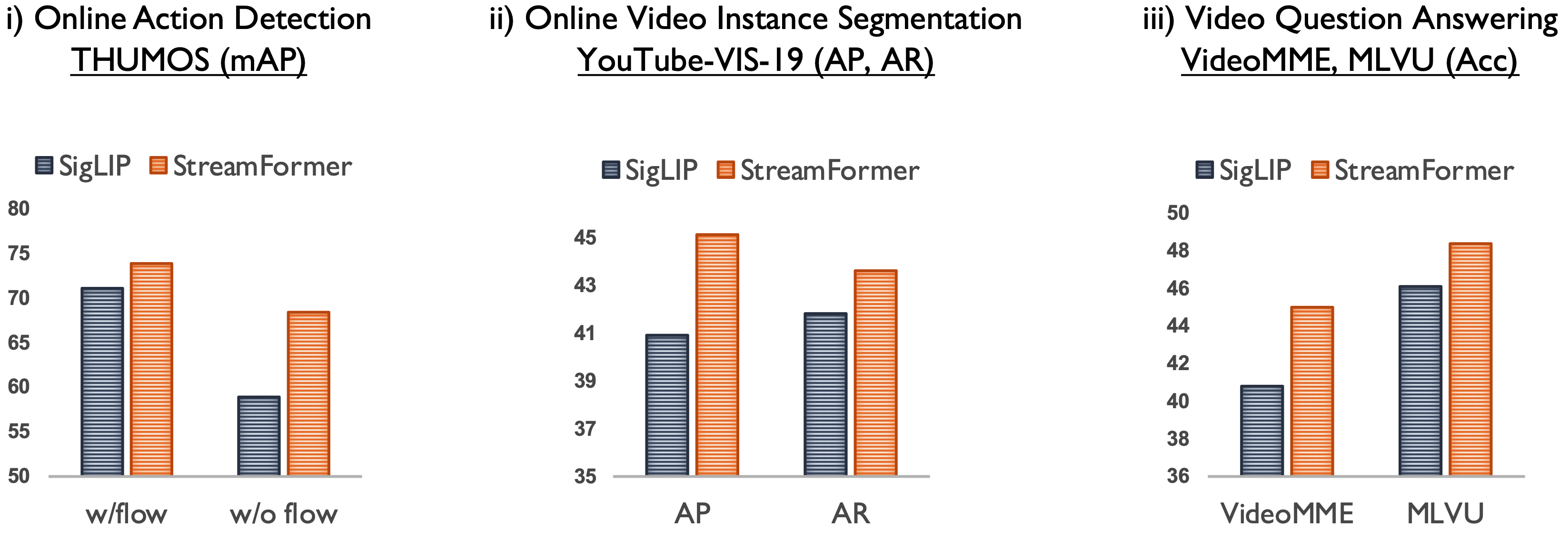
We present our downstream performance on three tasks: Online Action Detection, Online Video Instance Segmentation, and Video Question Answering.
Our baseline is the original image encoder of SigLIP,
i.e., without multitask training and temporal modeling.
It can be inferred that our streamformer achieves significantly better performance than the baseline on all downstream tasks, including online action detection, online video instance segmentation, and video question answering.
We present our downstream performance on three tasks: Online Action Detection, Online Video Instance Segmentation, and Video Question Answering. Our baseline is the original image encoder of SigLIP, i.e., without multitask training and temporal modeling. It can be inferred that our streamformer achieves significantly better performance than the baseline on all downstream tasks, including online action detection, online video instance segmentation, and video question answering.
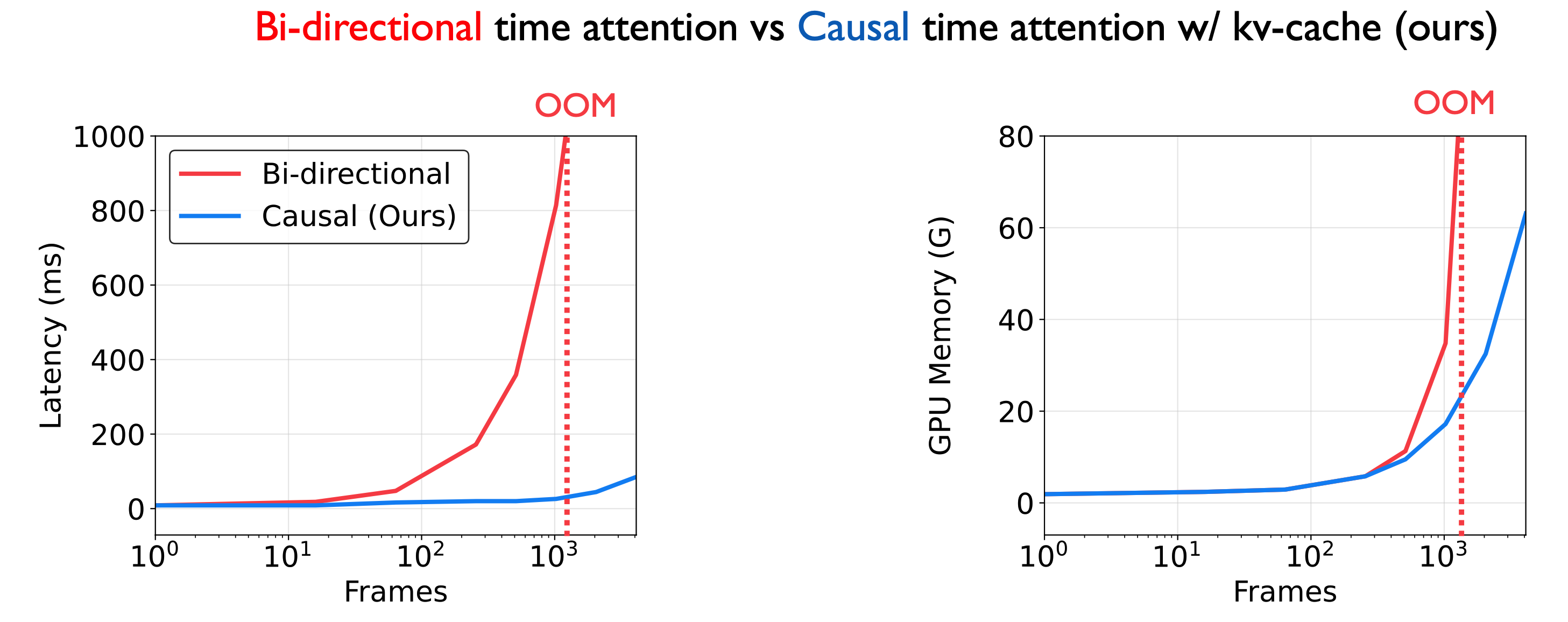
Equipped with KV cache, our StreamFormer achieves a significant reduction in inference latency and memory consumption compared to the bi-directional attention baseline.
The KV cache mechanism allows the model to store and reuse previously computed key-value pairs when inferencing, enabling efficient processing of streaming video data.
Equipped with KV cache, our StreamFormer achieves a significant reduction in inference latency and memory consumption compared to the bi-directional attention baseline. The KV cache mechanism allows the model to store and reuse previously computed key-value pairs when inferencing, enabling efficient processing of streaming video data.
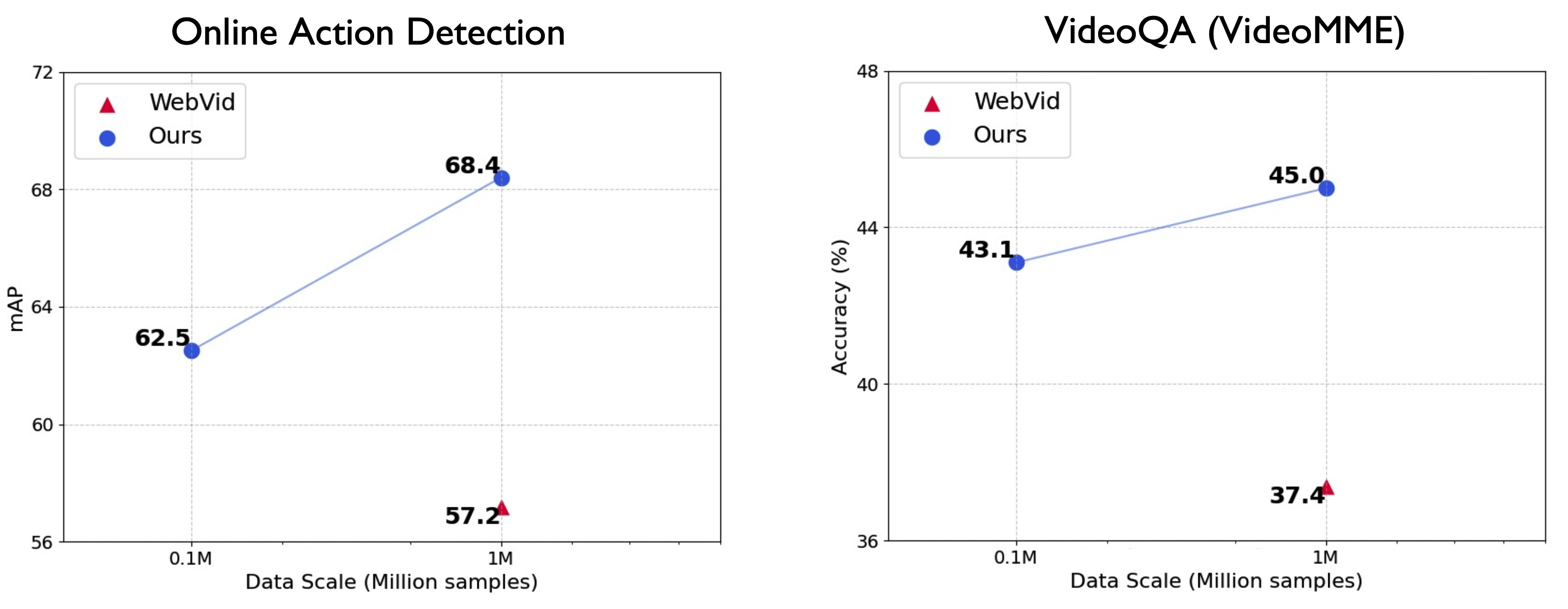
With our proposed multitask training strategy, we can achieve competitive performance compared to the video-text contrastive baseline.
We randomly select 1M video-text pairs from WebVid-10M, which is comparable to the scale of our pre-training data.
The models trained on WebVid-1M exhibit relatively low performance, possibly due to insufficient pre-training data for video-text contrastive learning.
In comparison, our approach outperforms WebVid-1M model even using only 0.1M pre-training data, significantly reducing the computational cost for training.
With our proposed multitask training strategy, we can achieve competitive performance compared to the video-text contrastive baseline. We randomly select 1M video-text pairs from WebVid-10M, which is comparable to the scale of our pre-training data. The models trained on WebVid-1M exhibit relatively low performance, possibly due to insufficient pre-training data for video-text contrastive learning. In comparison, our approach outperforms WebVid-1M model even using only 0.1M pre-training data, significantly reducing the computational cost for training.