BibTeX
@inproceedings{yan-xie-2024-echosight,
title = "{E}cho{S}ight: Advancing Visual-Language Models with {W}iki Knowledge",
author = "Yan, Yibin and
Xie, Weidi",
editor = "Al-Onaizan, Yaser and
Bansal, Mohit and
Chen, Yun-Nung",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2024",
month = nov,
year = "2024",
address = "Miami, Florida, USA",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.findings-emnlp.83",
pages = "1538--1551",
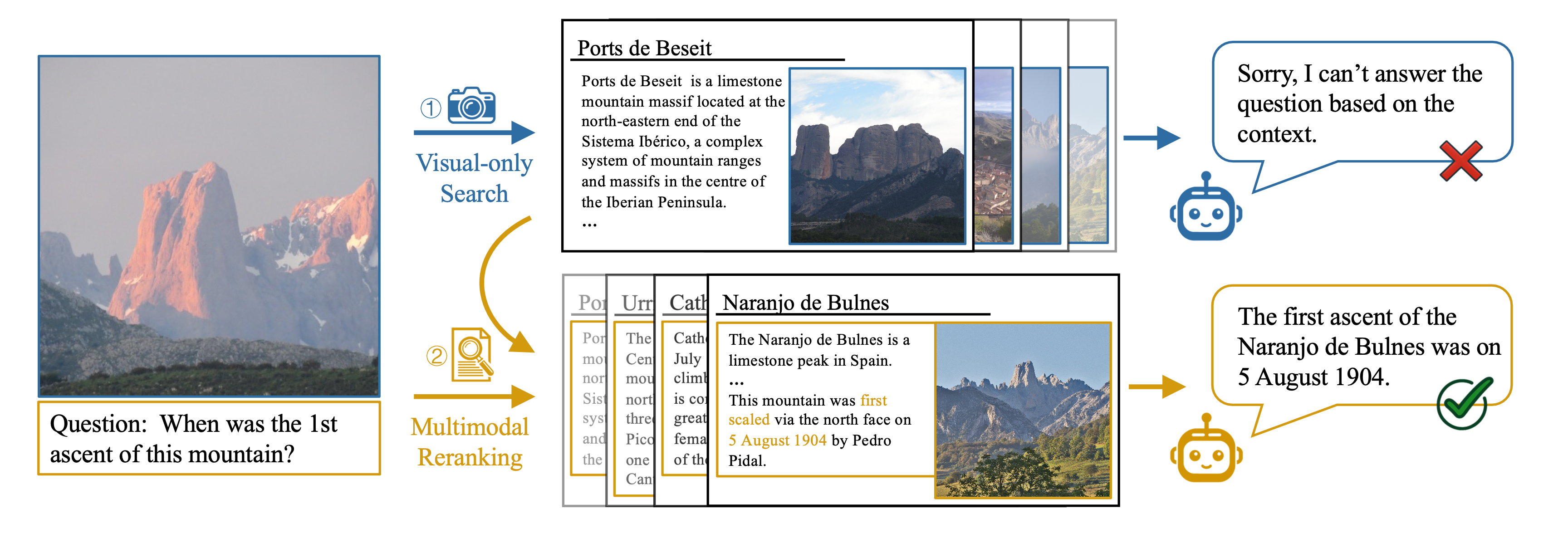
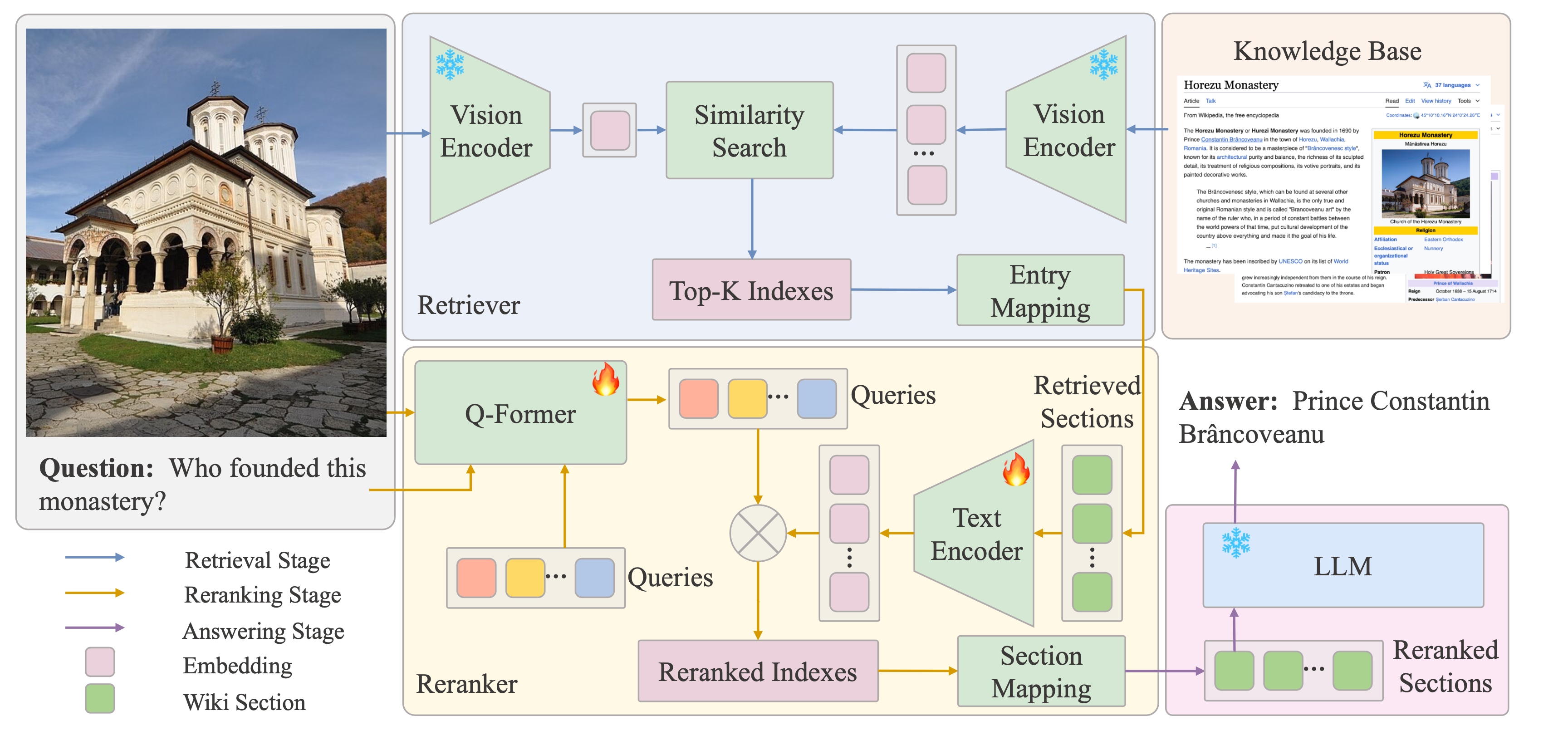
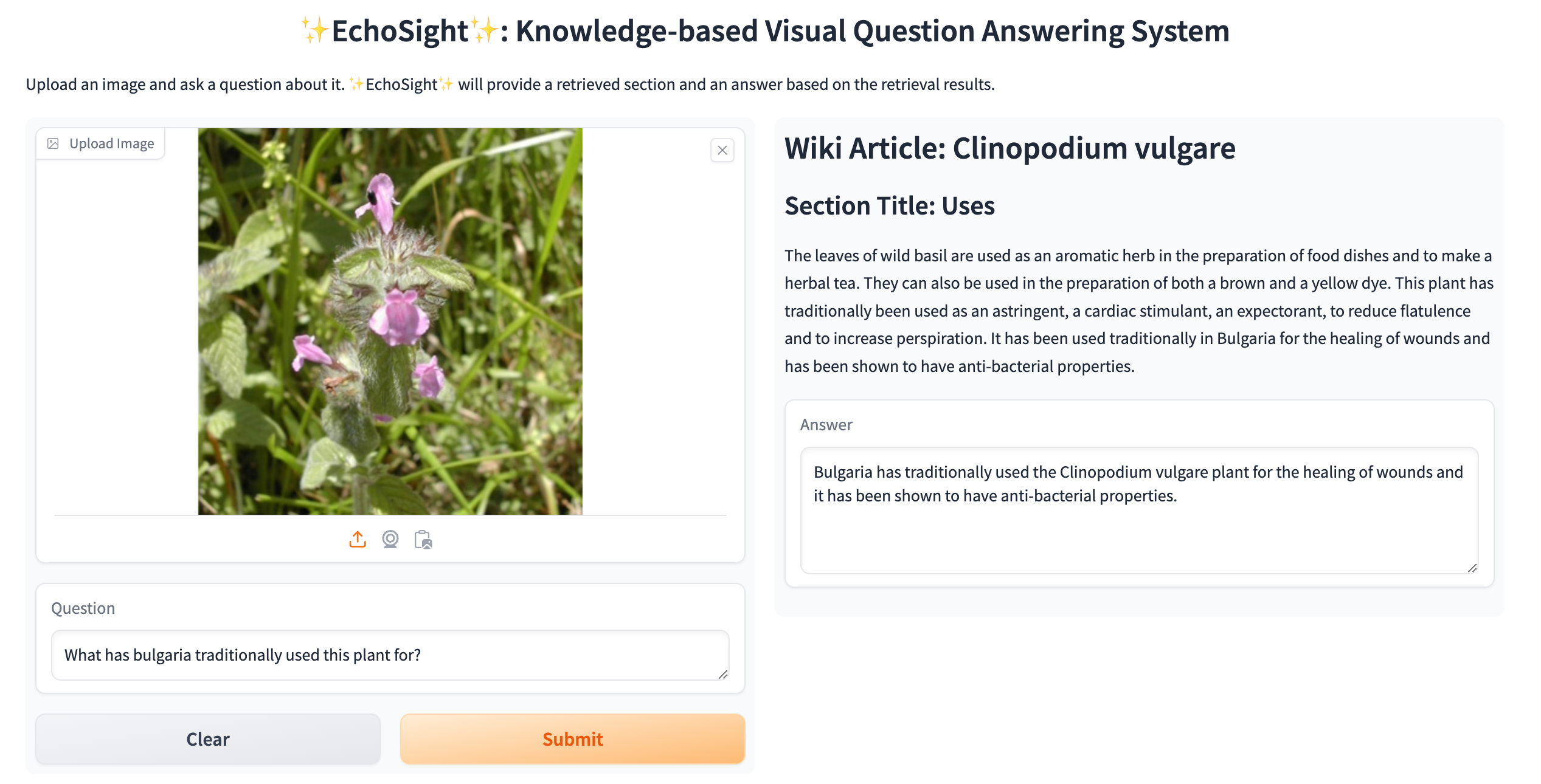
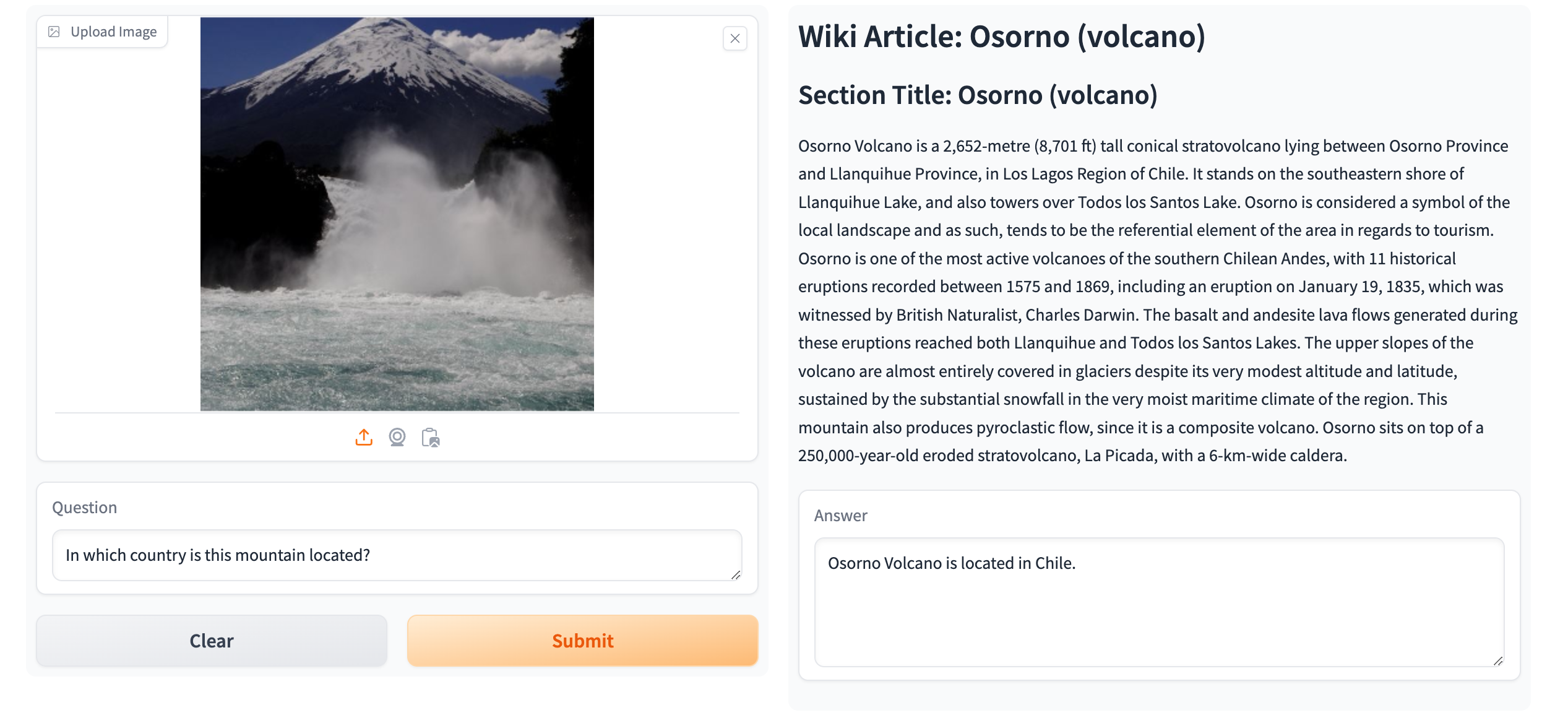
abstract = "Knowledge-based Visual Question Answering (KVQA) tasks require answering questions about images using extensive background knowledge. Despite significant advancements, generative models often struggle with these tasks due to the limited integration of external knowledge. In this paper, we introduce **EchoSight**, a novel multimodal Retrieval-Augmented Generation (RAG) framework that enables large language models (LLMs) to answer visual questions requiring fine-grained encyclopedic knowledge. To strive for high-performing retrieval, EchoSight first searches wiki articles by using visual-only information, subsequently, these candidate articles are further reranked according to their relevance to the combined text-image query. This approach significantly improves the integration of multimodal knowledge, leading to enhanced retrieval outcomes and more accurate VQA responses. Our experimental results on the E-VQA and InfoSeek datasets demonstrate that EchoSight establishes new state-of-the-art results in knowledge-based VQA, achieving an accuracy of 41.8{\%} on E-VQA and 31.3{\%} on InfoSeek.",
}